【面试题】JAVA面试题之大杂烩篇

【面试题】JAVA面试题之大杂烩篇
時光StringBuilder与StringBuffer的区别
StringBuilder 和 StringBuffer 都是 Java 中用于处理字符串的可变类,但它们之间有一些关键的区别:
1. 线程安全性
StringBuffer: 是线程安全的。它的所有公共方法都是同步的(即使用了 synchronized 关键字),这意味着在多线程环境中,多个线程可以安全地访问同一个 StringBuffer 实例,而不会导致数据不一致或其他并发问题。
StringBuilder: 不是线程安全的。它的方法没有使用 synchronized 关键字,因此在多线程环境中使用 StringBuilder 可能会导致数据不一致或其他并发问题。
2. 性能
StringBuilder: 由于没有同步开销,StringBuilder 在单线程环境中的性能通常比 StringBuffer 更好。如果你确定你的代码只会在单线程环境中运行,使用 StringBuilder 可以获得更好的性能。
StringBuffer: 由于方法的同步,StringBuffer 在多线程环境中的性能可能会稍差一些,但它在多线程环境中提供了线程安全性。
3. 使用场景
StringBuilder: 适用于单线程环境或不需要线程安全的场景。例如,在循环中频繁地拼接字符串时,使用 StringBuilder 可以提高性能。
StringBuffer: 适用于多线程环境或需要线程安全的场景。例如,在多个线程同时访问和修改同一个字符串对象时,使用 StringBuffer 可以确保数据的一致性。
4. API 兼容性
StringBuilder 和 StringBuffer 的 API 几乎是完全相同的,因此你可以很容易地在它们之间切换,而不需要修改太多的代码。
总结
StringBuilder: 适用于单线程环境,性能更好。
StringBuffer: 适用于多线程环境,提供了线程安全性。
在实际开发中,如果你不需要考虑线程安全问题,建议使用 StringBuilder 以获得更好的性能。如果你需要在多线程环境中操作字符串,则应该使用 StringBuffer。
自动拆箱与自动装箱
在 Java 中,自动装箱(Autoboxing)和自动拆箱(Unboxing)是 Java 5 引入的两个特性,它们使得基本数据类型和其对应的包装类之间的转换变得更加方便。
自动装箱(Autoboxing)
自动装箱是指将基本数据类型(如 int、char、boolean 等)自动转换为其对应的包装类对象(如 Integer、Character、Boolean 等)。
示例
1 | int primitiveInt = 42; |
在这个例子中,int 类型的 primitiveInt 被自动转换为 Integer 类型的 wrappedInt。
自动拆箱(Unboxing)
自动拆箱是指将包装类对象(如 Integer、Character、Boolean 等)自动转换为其对应的基本数据类型(如 int、char、boolean 等)。
示例
1 | Integer wrappedInt = 42; |
在这个例子中,Integer 类型的 wrappedInt 被自动转换为 int 类型的 primitiveInt。
使用场景
自动装箱和自动拆箱在以下场景中非常有用:
集合类:集合类(如
ArrayList、HashMap等)只能存储对象,不能存储基本数据类型。自动装箱使得你可以直接将基本数据类型存储在集合中。java1
2
3ArrayList<Integer> list = new ArrayList<>();
list.add(1); // 自动装箱
int value = list.get(0); // 自动拆箱方法参数和返回值:方法可以接受和返回包装类对象,自动装箱和自动拆箱使得你可以直接传递和返回基本数据类型。
java1
2
3
4
5public Integer add(Integer a, Integer b) {
return a + b; // 自动拆箱和自动装箱
}
int result = add(1, 2); // 自动装箱和自动拆箱条件表达式:在条件表达式中,自动装箱和自动拆箱使得你可以直接使用基本数据类型和包装类对象。
java1
2
3
4Integer wrappedInt = 42;
if (wrappedInt == 42) { // 自动拆箱
System.out.println("Equal");
}
注意事项
性能开销:虽然自动装箱和自动拆箱使得代码更加简洁,但它们可能会带来一些性能开销,因为涉及到对象的创建和销毁。
空指针异常:在自动拆箱时,如果包装类对象为
null,会抛出NullPointerException。java1
2Integer wrappedInt = null;
int primitiveInt = wrappedInt; // 抛出 NullPointerException
总结
自动装箱和自动拆箱是 Java 中非常方便的特性,它们简化了基本数据类型和包装类之间的转换。然而,在使用时需要注意性能开销和可能的空指针异常。
实战演练
下面的程序返回的结果分别是什么,为什么?
1 | public static void main(String[] args) { |
自动装箱和缓存机制
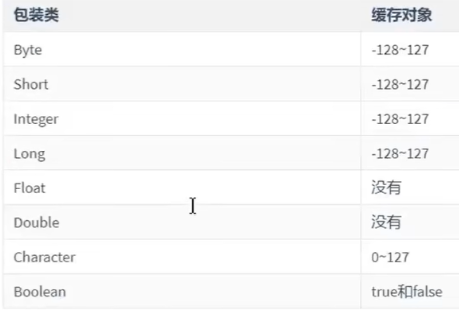
Java 的 Integer 类有一个缓存机制,它会缓存从 -128 到 127 之间的整数对象。这意味着在这个范围内的整数在自动装箱时会返回同一个缓存对象,而不是创建新的 Integer 对象。
各包装类型缓存对象范围:
具体分析
Integer i1 = 100; 和 Integer i2 = 100;
由于 100 在 -128 到 127 的范围内,i1 和 i2 都会引用同一个缓存的 Integer 对象。
因此,i1 == i2 返回 true。
Integer i3 = 128; 和 Integer i4 = 128;
由于 128 超出了 -128 到 127 的范围,i3 和 i4 都会创建新的 Integer 对象。
因此,i3 == i4 返回 false,因为它们引用的是不同的对象。
输出结果
1 | true |
总结
对于 -128 到 127 范围内的整数,自动装箱会返回同一个缓存的 Integer 对象,因此 == 比较返回 true。
对于超出这个范围的整数,自动装箱会创建新的 Integer 对象,因此 == 比较返回 false。
进一步解释
如果你想比较两个 Integer 对象的值是否相等,而不是比较它们是否引用同一个对象,应该使用 equals 方法:
1 | System.out.println(i1.equals(i2)); // true |
equals 方法会比较两个 Integer 对象的值,而不是它们的引用。
如何定义一个标准javabean
在 Java 中,一个标准的 JavaBean 是一个遵循特定命名和设计约定的类。JavaBean 通常用于封装数据,并且可以通过反射机制进行访问和操作。以下是定义一个标准 JavaBean 的主要规范:
私有属性(Private Fields)
JavaBean 的属性通常是私有的(private),这意味着它们不能直接从类的外部访问。
公共的 getter 和 setter 方法
为了访问和修改私有属性,JavaBean 提供了公共的 getter 和 setter 方法。这些方法的命名遵循特定的约定:
Getter 方法:用于获取属性的值。如果属性名为 propertyName,则 getter 方法通常命名为 getPropertyName()。如果属性是布尔类型,getter 方法可以命名为 isPropertyName()。
Setter 方法:用于设置属性的值。如果属性名为 propertyName,则 setter 方法通常命名为 setPropertyName(Type value)。
无参构造方法
JavaBean 必须提供一个无参的公共构造方法(默认构造方法),以便可以通过反射机制实例化对象。
实现 Serializable 接口(可选)
为了支持序列化和反序列化,JavaBean 可以实现 java.io.Serializable 接口。
选择合适的数据类型
- 基本数据类型:适用于不需要表示
null值的场景,性能更好,代码更简洁。 - 包装类:适用于需要表示
null值的场景,例如数据库操作或集合类。
在实际开发中,选择使用基本数据类型还是包装类取决于具体的需求和场景。如果不需要表示 null 值,并且性能是一个关键因素,建议使用基本数据类型。如果需要表示 null 值,或者需要将属性存储在集合中,建议使用包装类。
关键点总结
私有属性:属性通常是私有的,以封装数据。
Getter 和 Setter 方法:提供公共的 getter 和 setter 方法来访问和修改私有属性。
无参构造方法:提供一个无参的公共构造方法,以便可以通过反射机制实例化对象。
实现 Serializable 接口(可选):为了支持序列化和反序列化,可以实现 Serializable 接口。
死锁及产生死锁的原因,应如何避免
死锁(Deadlock)
死锁是指两个或多个线程在等待彼此释放资源的情况下,永远无法继续执行的状态。死锁是并发编程中常见的问题,通常发生在多个线程需要竞争多个资源时。
死锁的四个必要条件
死锁的发生需要满足以下四个必要条件:
互斥条件(Mutual Exclusion):
至少有一个资源必须处于非共享模式,即一次只能被一个线程使用。如果另一个线程请求该资源,请求线程必须等待。
占有并等待(Hold and Wait):
一个线程必须占有至少一个资源,并且正在等待获取其他线程占有的资源。
不可抢占(No Preemption):
资源不能被强制从占有它的线程中抢占,只能由占有它的线程显式释放。
循环等待(Circular Wait):
存在一组等待线程,形成一个循环链,每个线程都在等待链中下一个线程占有的资源。
死锁的原因
死锁通常由以下原因引起:
资源竞争:
多个线程需要竞争多个资源,而这些资源被不同的线程占有。
资源请求顺序不当:
线程请求资源的顺序不当,导致循环等待。例如,线程 A 占有资源 1 并请求资源 2,而线程 B 占有资源 2 并请求资源 1。
资源分配不当:
资源分配策略不当,导致某些线程长时间占有资源,而其他线程无法获取所需资源。
如何避免死锁
避免死锁的方法主要包括以下几种:
破坏互斥条件:
尽量避免使用非共享资源。如果资源可以共享,则不会发生死锁。
破坏占有并等待条件:
一次性请求所有需要的资源。如果线程在开始执行前请求所有需要的资源,并且在所有资源都可用之前不执行,则可以避免占有并等待条件。
破坏不可抢占条件:
允许资源被抢占。如果资源可以被强制从占有它的线程中抢占,则可以避免死锁。
破坏循环等待条件:
对资源进行排序,并强制线程按照相同的顺序请求资源。如果所有线程都按照相同的顺序请求资源,则不会形成循环等待。
示例
以下是一个简单的死锁示例:
1 | public class DeadlockExample { |
在这个示例中,thread1 和 thread2 分别占有 resource1 和 resource2,并试图获取对方的资源,从而形成死锁。
避免死锁的示例
通过破坏循环等待条件,可以避免死锁:
1 | public class DeadlockAvoidanceExample { |
在这个示例中,thread2 先请求 resource1,再请求 resource2,从而避免了循环等待。
总结
死锁是并发编程中常见的问题,通常由资源竞争、资源请求顺序不当和资源分配不当引起。避免死锁的方法包括破坏互斥条件、占有并等待条件、不可抢占条件和循环等待条件。通过合理设计资源请求顺序和资源分配策略,可以有效避免死锁的发生。
TCP协议中的三次握手和四次挥手
三次握手:
- 第一次握手,客户端向服务器端发出连接请求,等待服务器确认。
- 第二次握手,服务器端向客户端回送一个响应,通知客户端收到了连接请求。
- 第三次握手,客户端再次向服务器端发送确认信息,确认连接。
四次挥手:
- 第一次挥手:客户端向
- 服务器端提出结束连接,让服务器做最后的准备工作。此时,客户端处于半关闭状态,即表示不再向服务器发送数据了,但是还可以接受数据。
- 第二次挥手:服务器接收到客户端释放连接的请求后,会将最后的数据发给客户端。并告知上层的应用进程不再接收数据。
- 第三次挥手:服务器发送完数据后,会给客户端发送一个释放连接的报文。那么客户端接收后就知道可以正式释放连接了。
- 第四次挥手:客户端接收到服务器最后的释放连接报文后,要回复一个彻底断开的报文。这样服务器收到后才会彻底释放连接。这里客户端,发送完最后的报文后,会等待2MSL,因为有可能服务器没有收到最后的报文,那么服务器迟迟没收到,就会再次给客户端发送释放连接的报文,此时客户端在等待时间范围内接收到,会重新发送最后的报文,并重新计时。如果等待2MSL后,没有收到,那么彻底断开。
时间复杂度
时间复杂度(Time Complexity)是算法分析中的一个重要概念,用于衡量算法在输入规模增大时所需执行时间的增长趋势。时间复杂度通常用大 O 表示法(Big O Notation)来表示,它描述了算法在最坏情况下的执行时间与输入规模之间的关系。
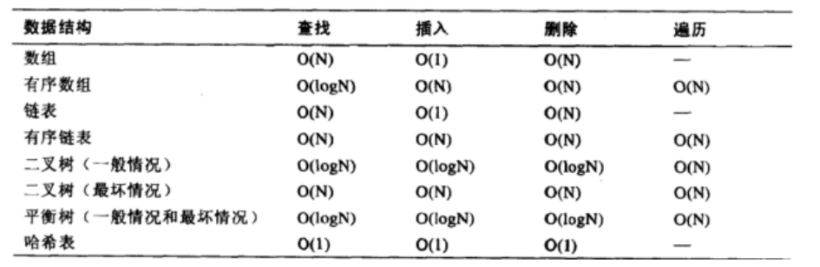
常见的时间复杂度
以下是一些常见的时间复杂度及其对应的算法性能:
O(1) - 常数时间复杂度:
- 算法的执行时间与输入规模无关,无论输入规模如何增大,执行时间都是固定的。
- 例如:访问数组中的某个元素、插入/删除链表中的某个节点。
O(log n) - 对数时间复杂度:
- 算法的执行时间随输入规模的增大而增长,但增长速度较慢,通常是对数级别的增长。
- 例如:二分查找(Binary Search)。
O(n) - 线性时间复杂度:
- 算法的执行时间与输入规模成正比,输入规模增大一倍,执行时间也增大一倍。
- 例如:遍历数组、线性查找(Linear Search)。
O(n log n) - 线性对数时间复杂度:
- 算法的执行时间介于线性和平方之间,通常是一些高效排序算法的时间复杂度。
- 例如:快速排序(Quick Sort)、归并排序(Merge Sort)。
O(n^2) - 平方时间复杂度:
- 算法的执行时间与输入规模的平方成正比,输入规模增大一倍,执行时间增大四倍。
- 例如:冒泡排序(Bubble Sort)、选择排序(Selection Sort)。
O(n^3) - 立方时间复杂度:
- 算法的执行时间与输入规模的立方成正比,输入规模增大一倍,执行时间增大八倍。
- 例如:矩阵乘法。
O(2^n) - 指数时间复杂度:
- 算法的执行时间随输入规模的增大呈指数级增长,通常是一些暴力搜索算法的时间复杂度。
- 例如:求解旅行商问题(TSP)的暴力解法。
O(n!) - 阶乘时间复杂度:
- 算法的执行时间随输入规模的增大呈阶乘级增长,通常是一些组合问题的暴力解法。
- 例如:求解全排列问题的暴力解法。
如何计算时间复杂度
计算时间复杂度通常需要分析算法中的基本操作次数,并找出其与输入规模之间的关系。以下是一些常见的计算方法:
循环结构:
- 单层循环的时间复杂度通常为 O(n)。
- 嵌套循环的时间复杂度通常为 O(n^k),其中 k 是循环的层数。
递归结构:
- 递归算法的时间复杂度通常需要通过递归关系式来求解,例如使用主定理(Master Theorem)。
分治法:
- 分治法的时间复杂度通常可以通过递归关系式来求解,例如归并排序的时间复杂度为 O(n log n)。
总结
时间复杂度是衡量算法性能的重要指标,它描述了算法在最坏情况下的执行时间与输入规模之间的关系。了解常见的时间复杂度及其对应的算法性能,有助于选择合适的算法来解决问题,并优化算法的执行效率。




















